
Программирование на perl — примеры
# members, значением которой будет
# массив @members.
$TV{$rec->{flins}}=$rec; # Запоминаем все, что получили.
# Для этого формируем самую
# внешнююю пару %TV по ключу
# flins со значением указателя на
# хеш $rec.
Можно использовать поля внешних указателей для того, чтобы не было дублирования данных.
Пример. Мы желаем включить поле "kids" в запись. Это может быть ссылка на список, содержащий указатель на записи о детях.
foreach $family # пробегаем по ключам самых
# внешних пар, то-есть по
# фамилиям
(keys %TV)
{
me $rec = $TV {$family}; # $rec – это временный
# указатель на значения
# внешнего хеша.
# Внимание! $rec и
# $TV {$family} указывают на
# одно и тоже.
@kids=();
for $person (@{$rec->{members}}) # $person пробегает значения # по элементам массива
# @members.
{ if ($person->{role}=~/kid|son|daughter/)
# Из элемента выбираем значения хеша по ключу role, то-есть
# по ключу kid, son или daughter.
{
push @kids, $person; # Если мы получили одно из
# этих трех значений, то
# этот весь элемент массива
# записываем в массив @kids.
}
}
$rec->{kids}=[@kids]; # формируем еще одну пару
# хеша, состоященго из
# элементов, содержащих
# "детей".
}
Теперь любая семья имеет четыре ключа: series, days, members и kids.
Изменим возраст "bart".
 $TV{simps}{kids}[0]{age}++;
$TV{simps}{kids}[0]{age}++;
тогда мы меняем также же элемент это указатели на
print $TV{simps}{members}[2]{age}; один и тот же элемент
Печать всей структуры
foreach $family (keys%TV) # печать фамилии каждого
# семейства
{ print "The $family";
print "is during @{$TV{$family}{days}}n"; # печать дней
print "its members are:n";
for $who (@{$TV{$family}{members}}) # $who являются
# указателями на
# элементы массива
# @members, то-есть
# принимает значения
# типа 1, 2, 3.
{ print "$who->{name},{$who->{role}}, age $who->{age}n";
# Печать значения по ключу name, потом по ключу role, а
# потом печать возраста, то-есть по ключу age.
}
print "it turns out that $TV{$family}{‘lead’} has";
print scalar (@($TV{$family}{kids})), "kids named";
print join (", ",map{$_->{name}}@{$TV{$family}{$kids}});
print "n";
}
Здесь $_ — приинимает значения указателя @{$TV{$family}{kids}}, а потом она применяется для разыменовывания этого указателя — $_->{name}.
Функция map выдает результаты вычисления выражения, вычисленного в списочном контексте.
Пример 1:
@more = map $_+4,3,5,7
Здесь $_ принимает последовательно значения 3, 5, 7 и к ней каждый раз добавляется 4. Получаем 7, 9, 11.
Пример 2:
@square = map $_*$_ 1..10;
Здесь вычисляются квадраты первых десяти чисел.
Пример 3:
%sizes = map {$_, — s} <*>;
Получаем хеш файлов и их размеров.
Пример 4:
@triangle = map 1..$_, 1..5;
Получаем следующие группы
1, 1,2, 1,2,3, 1,2,3,4, 1,2,3,4,5
Базы данных пользователя
Для работы применяется DBM-библиотека, в которой обеспечивается:
— запись пар ключ – значение в два файла;
— ввод и пополнение базы;
— удаление элементов.
Механизм DBM
Связывание DBM-базы с хешем. Этот хеш называется DBM массивом. Новый элемент в хеше влечет новый элемент в базу.
Удаление – аналогично. Существуют ограничения на объем баз и хешей.
1. Открытие и закрытие DBM — хеша
Для этого применяется функция:
dbmopen (%ИМЯ_МАСС,"имя_DBM_файла",$режим);
%ИМЯ_МАСС – это имя Perl–хеша. Если в данном хеше уже есть значения, то они выбрасываются.
имя_DBM_файла — это DBM-база, что соединяется с хешем.
База данных хранится в виде пары файлов:
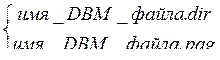
Параметр $режим – права доступа к этим двум файлам, если они создаются заново.
Пример: Открыть %FRED для my_base
dbmopen (%FRED,"my_base",0644);
Этот вызов связывает хеш с файлами my_base.dir и my_base.pag, расположенными в текущем каталоге. Если эти файлы не существуют, то они создаются с правом доступа 0644.
Функция dbmopen возвращает:
true – если базу можно открыть или создать;
false – иначе.
Если не надо создавать файлы, то вместо параметра $режим указывается значение undef.
Пример:
dbmopen (%A,"x-file", undef)|| die "cannot open DBM x_file";
Если эти файлы x-file. dir и x-file. pag открыть нельзя, то вызов возвращает "ложь" без попытки создать эти файлы.
Для закрытия баз
а)dbmclose (%ИМЯ_МАССИВА);
Если закрыть нельзя, то возвращает ложь
б) Завершение программы также ведет к закрытию баз
2. Использование DBM-хеша
$FRED{"fred"}="bedrock"; # это создать или обновить элемент
# в базе
delete $FRED{"barney"}; # удалить элемент базы данных
foreach $key (keys %FRED) # пройти по всем значениям. Этот
# цикл должен просматривать весь
# файл на диске дважды, один раз
# для выборки ключей, дркгой – для
# поиска значений при печати.
{ print "$key: value=%FRED{$key}n";
}
while (($key,$value)= each(%FRED)) # при использовании операции
# each делается всего один
# проход.
{ print "$key:value=$valuen";
}
Базы с записями фиксированной длины
Это еще один способ хранения данных. В них обеспечивается произвольный доступ, так как известна длина записи.
Процедура действий:
1. Открытие файла для чтения и записи.
2. Переход в файле на произвольную позицию.
3. Выборка данных фиксированной длины, то-есть в этом случае выборка производится не символа "конец строки".
4. Запись данных блоками фиксированной длины.
В п.1 в функции open перед способом открытия файла, надо поставить знак "+", который говорит о том, что данный файл открывается для чтения и для записи.
Пример 1. Открыть файл b для записи и чтения (будет ошибка, если он отсутствует).
open(A,"+<b");
Пример 2. Создать файл d для записи и чтения.
open (C,"+>d");
Пример 3. Открыть или создать файл f для записи и чтения
open (E,"+>>f");
В п.2. применяется функция seek.
seek (ДЕСКРИПТОР, смещение, точка_отсчета);
ДЕСКРИПТОР – это дескриптор файла.
Смещение+точка_отсчета — это абсолютная позиция для следующего чтения или записи в базе (то-есть в файле).
Внимание! Часто точка_отсчета равна нулю.
Пример. Пусть длина равна 83, где 83 – длина каждой записи в файле. Для перехода к 5-й записи необходимо:
seek(FILE,4*83,0);
В п.3 для выборки применяется функция read.
*** Пример. Будем ссылаться на этот пример в дальнейшем.
$count=read (FILE,$buf,83);
FILE – дескриптор файла
$buf – скалярная переменная, куда записываются
83 — количество байтов, что надо прочитать
Функция возвращает количество фактически прочитанных файлов. Как правило это число равно затребованному количеству байтов, если только файл был открыт и если мы оказались не слишком близко к концу файла.
В п.4 для записи применяется функция print.
Для формирования записи правильной длины надо использовать функцию pack.
Пример. В файл с дескриптором FILE записывается запись из 83 символов.
print FILE pack ("A40 A A40 s",$f1,$f2,$f3,#f4);
Здесь – 40 символов для $f1,
— 1 символ для $f2,
— 40 символов для $f3,
— 2 байта (короткое целое) для $f4.
Упаковка и распаковка двоичных данных
1. Функция pack схожа с функцией sprintf.
2.
Получает:
— строка формата;
— список значений
Выдает:
— упакованное значение в одну строку
$buf=pack("CCCC",140,168,65,25);
Здесь строка формата pack — четыре буквы C.
Каждая С – один байт (поэтому здесь может быть число не более 255, то-есть короткон целое), вычисляемый из символьного значения без знака.
$buf – это четырехсимвольная строка, в которой любому символу один байт.
Байты равны 140,168,65,25 соответственно.
Формат l – длинное значение со знаком.
$buf=pack("l",0x41424344);
Этот оператор выдает четырехсимвольную строку, которая может быть ABCD или DCBA. Это зависит от того, какой порядок хранения байтов используется в компьютере:
— "младший в младшем" или
— "старший в старшем".


