Программирование и алгоритмические языки — коллизия
Коллизия
Коллизия подразумевает то, что одно и то же имя определяется по-разному.
С помощью квалифицированных имён можно избавиться от коллизии.
Если имя неквалифицированное (просто f), то имеется в виду ближайшее определение процедуры.
Вспомним понятие области действия:
Если какая-то переменная описана там и здесь (и ничего больше не сказано), то в данном случае выбирается ближайшее определение.
Если нужно указать определённую функцию из какого-нибудь модуля, нужно осуществить указание на тот модуль, где находится данная функция.
Например, М. f, где М — название модуля, а f- функция.
Замечание: можно ли определять одинаковые имена на одном уровне в одном модуле?
— В процедурном программировании это было категорически запрещено.
— В модульном программировании чуть-чуть иначе.
Что такое имя процедуры?
а) A*B R*R->R (функция от двух переменных) , где R –вещественные числа
(1 аргумент = вещественный)*(2 аргумент = вещественный)->(результат =вещественный))
n
б) П ai R*->R, где R*- последовательность
i=1
((1 аргумент =последовательность)->(результат =вещественный))
а) и б)- две разные функции, т. к. у них разные типы
Соглашение:
Можно использовать одинаковые имена процедур и функций на одном уровне, если у них разный список параметров.
Итак:
-имена функций являются одинаковыми, если у них заголовки в точности идентичны;
-если имя функций одно, а параметры разные, то эти функции считаются разными;
Это по-другому называется override – перегрузка (переопределение).
Override — добавление новых имён с учётом регулировки коллизий и синтаксических соглашений.
Тот же вид наследования возможен и в ООП, но наследование здесь не множественное, не кратное. Иначе говоря, каждый тип или класс может ссылаться лишь на одного предка.

Это не отражает всю сложность реальности.
Тип данных -> Модуль-> Класс
ООП как оперирование типами
В объектно-ориентированном программировании типы рассматриваются как значения.
Структура модульного программирования — произвольный граф без циклов.
Структура ООП — дерево.
Манипуляция над типами производится при помощи именования типов.
Заметим, что:
—В процедурном программировании понятие типа сильно ориентировано на значения. Классификация типов производится по области значений и именуются области значений, а не var.
—Модульное программирование допускает именование типа, если отождествлять модуль с реализацией типа (в реальности ни синтаксис, ни общепринятая практика не связывают понятие модуля с понятием типа).
Замечание:
Модуль можно трактовать как определение нескольких типов. Можно сказать, что модуль- библиотека, т. е. произвольный набор определённых значений и преобразований.
— В объектно-ориентированном программировании типы рассматриваются как
значения.
Краткий синтаксис языка C#
Using System;
Namespace [имя_приложения]
{
…
// описание тех классов, которые используем
Class [имя класса]
{
}
…
Class Program
{
// основная программа — запускалка
static void Main()
}
}
System — стандартная библиотека — ввод-вывод, базовые классы.
Директива Using позволяет обращаться к членам пространства имён напрямую (без использования полного имени).
Замечание: при необходимости можно подключить другие библиотеки
Как мы знаем, каждое приложение должно начинаться с какого-то оператора. Несмотря на то, что в приложении может быть много классов, точка входа всегда одна. В C# при запуске приложения начинает выполняться метод Main.
Namespace — логически связанное определение имён. Пространства имён (Namespace) предоставляют возможность логичной взаимосвязи классов и других типов.
Именование типов в C#
Тип данных «класс»
Основным элементом программы, созданной в объектно-ориентированном стиле, является класс.
Переменные типа «класс» называются объектами. В реальности определяется не сам объект, а ссылка на него – факт, который в синтаксисе явным образом нигде не указывается.
Семантика: класс — именованный тип данных. Класс определяет тип данных для описания множества объектов с одинаковым набором свойств и поведением.
Синтаксис определения классов:
[атрибуты];
[модификаторы доступа];
class (имя_класса) [: базовый класс [, интерфейсы] ]
{
//поля класса
(список полей Field1,…,Fieldk)
…….
//методы класса
(список объявлений методов с реализацией: Method1,…,Methodn)
…….
// свойства класса
…….
// события класса
…….
// подклассы, делегаты
}, где:
Fieldii – в точности как при описании типа «запись», только с некоторыми дополнительными опциями.
Methodi – заголовок функции с реализацией
Замечание:
Объявление (определение) класса помещается в логически связанное определение имён, т. е. в namespace с определением методов (реализацией, телом функции) и полей.
Для использования представления в C#, сохранённого в другом модуле необходимо осуществить операцию СБОРКИ.
Сборки могут содержать один или несколько модулей. Например, крупные проекты могут быть спланированы таким образом, чтобы несколько разработчиков работали каждый над своим модулем, а вместе эти модули образовывали одну сборку.
Конструкторы и деструкторы
Как переменные динамического типа, сами объекты создаются и уничтожаются в ходе выполнения.
Среди методов класса явно выделяют конструкторы и деструкторы, что явным образом отражается в синтаксисе:
—Constructor (конструктор — процедура создания объекта по ссылке):
Class name_of_the_class
{
…
name_of_the_class (FP); //, где FP – список формальных параметров
…
}
Если класс или структура создаются, то вызывается его конструктор. Конструкторы имеют то же имя, что и класс или структура. Они обычно инициализируют элементы данных нового объекта.
—Destructor (деструктор — метод, который будет вызываться непосредственно перед окончательным уничтожением объекта системой "сборки мусора".):
Class name_of_the_class
{
…
~ name_of_the_class (FP); // , где FP – список формальных параметров
{
// код деструктора
}
…
}
Замечание: система "сборки мусора" в С# освобождает память от лишних объектов автоматически, действуя незаметно и без всякого вмешательства со стороны программиста.
"Сборка мусора" происходит следующим образом:
Если ссылки на объект отсутствуют, то такой объект считается ненужным, и занимаемая им память в итоге освобождается и накапливается. Эта утилизированная память может быть затем распределена для других объектов.
"Сборка мусора" происходит лишь время от времени по ходу выполнения программы. Она не состоится, если существует один или более объектов, которые больше не используются. Следовательно, нельзя заранее знать или предположить, когда именно произойдет "сборка мусора".
Тем не менее инициализация "сборки мусора" вручную в большинстве случаев не рекомендуется, поскольку это может привести к снижению эффективности программы. Кроме того, у системы "сборки мусора" имеются свои особенности — даже если запросить "сборку мусора" явным образом, все равно нельзя заранее знать, когда именно будет утилизирован конкретный объект.
Помимо базовой семантики класса как именованного типа, понятие класса связывается с дополнительными способами описания и использования абстрактных типов, которые обычно формулируются в терминах трёх основных понятий: инкапсуляция, наследование и полиморфизм.
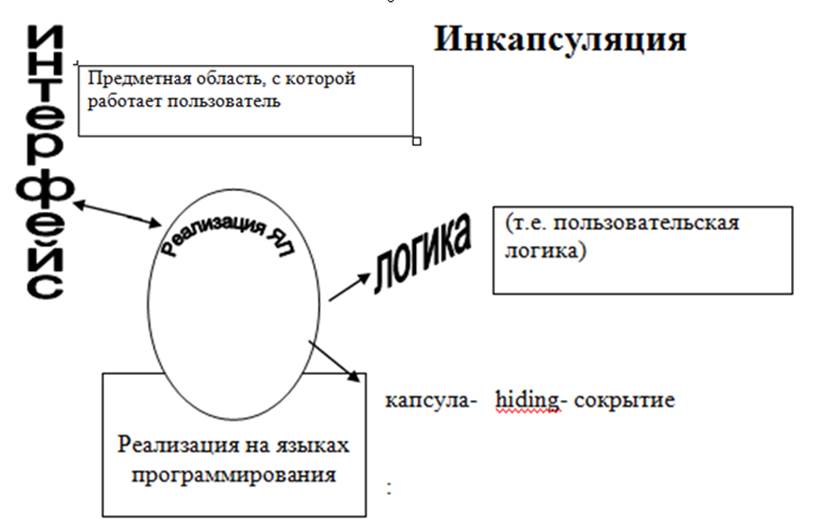 Инкапсуляция данных
Инкапсуляция данных
Инкапсуляция — кибернетика – функциональное описание систем, слишком сложных для классического анализа.
В этом понятии скрыта идея чёрного и серого ящиков. Строение интересует настолько, насколько оно определяет поведение. Это нужно для того, чтобы скрыть сложность реализации.
Принцип инкапсуляции не является программистским, а является общеметодическим (функциональным, бихевиористским). Его сформулировал Норберт Винер.
Идея инкапсуляции — идея явного разделения логики и реализации с целью сокрытия сложности не нова в программировании:
1) языки высокого уровня скрывают идеи реализации той машинной программы, в которой они транслируются (такие как Фортран, Кобол, Алгол, Pascal, Java, C, C++, C#, Objective C, Smalltalk, Delphi и т. д.)
2) пользовательские процедуры и функции скрывают детали алгоритма определения функции от самой функции
3) любое наименование скрывает детали алгоритма
4) в модульном программировании это определяется так:
Interface (public )-доступный пользователю |
![]() это старая идея локализации
это старая идея локализации
Таким образом, идея локализации в объектно – ориентированном программировании приобретает ОТНОСИТЕЛЬНЫЙ СМЫСЛ: не только что прятать, но и от кого прятать.
Для реализации ограничения доступа применяются модификаторы доступа — PUBLIC, PRIVATE, PROTECTED, INTERNAL.
—public- расширяет область видимости (можно обращаться из любого места программы)
—private- обеспечивает самую жёсткую локализацию, ограничивая доступ (область видимости) пределами описания данного класса (т. е. пользователь не видит private- полей и методов, а обращение к этим полям является синтаксической ошибкой)
—protected- виден классам-наследникам. Это даёт возможность скрыть от наследников переменную так, чтобы они не «напортачили» в ней.
—internal— модификатор доступа, который используется для методов, доступных всем классам, определённым в конкретной сборке
Public и private нужны для разделения логики и реализации (сокрытие реализации) — идея «чёрного ящика»
Организация памяти:
Процедуры и функции хранятся в памяти и именуются точно также как данные (т. е. явное пользовательское именование в языках высокого уровня, а адреса на нижнем уровне).
//Пример: Описать класс РАЦИОНАЛЬНЫЕ ЧИСЛА.
using System; //стандартная библиотека — ввод-вывод, базовые классы
namespace Fraction //логически связанное определение имён (Пространства имён (namespace) предоставляют возможность логической взаимосвязи классов и других типов.)
{
class tRational
{//поля — см. далее Сокрытие данных (set, get- подход)
public Int32 numerator; //числитель
public Int32 denominator;// знаменатель
//не в нормализованном виде, если нужно, то напиши метод
//методы:
//консольный ввод и вывод
private Int32 ReadInt(string s)
{
Console. WriteLine(s); //выводим на консоль информацию, которая содержалась в s
string input = Console. ReadLine(); // нет параметров, т. к. системный оператор
return Int32.Parse(input); // преобразование типов (читается строковое, а преобразуется в int)
}
public void read(string s)
{
Console. WriteLine(s);
numerator = ReadInt("Числитель: ");
denominator = ReadInt("Знаменатель: ");
}
private void WriteInt(string s, Int32 x)
{
Console. WriteLine(s);
Console. WriteLine(x. ToString()); //возвращает строку, представляющую текущий объект.
}
public void write(string s)
{
Console. WriteLine(s);
WriteInt("Числитель:", numerator);
WriteInt("Знаменатель:", denominator);
Console. ReadKey(); //задержка — получает следующий нажатый пользователем символ или функциональную клавишу. Нажатая клавиша отображается в окне консоли.
}
public void assign(tRational a)//присваивание значений- "клонирование"
{
this. numerator = a. numerator;
this. denominator = a. denominator;
}
public void add(tRational a) //добавить к this
{
this. numerator = this. numerator * a. denominator + a. numerator * this. denominator;
this. denominator = a. denominator * this. numerator;
}
public void subtract(tRational a) //вычесть из this
{
this. numerator = this. numerator * a. denominator — a. numerator * this. denominator;
this. denominator = a. denominator * this. numerator;
}
public void multiply(tRational a) //домножить
{
this. numerator = this. numerator * a. numerator;
this. denominator = a. denominator * this. denominator;
}
public void divide(tRational a)//поделить
{
this. numerator = this. numerator * a. denominator;
this. denominator = this. denominator * a. numerator;
}
} //tRational
class Program
{//программа-запускалка
//метод:
static void main()
{
//сложение двух дробей y<—y+x
tRational y, x; //указатели (объявление)
x = new tRational(); // вызов конструктора (выделение памяти)
y = new tRational();
y. read("Введите первое слагаемое:");
x. read("Введите второе слагаемое:");
y. add(x);
y. write("Сумма равна:");
}
}// Program
}// Fraction
Теперь возникает проблема сокрытия реализации данных.
Set-get подход
Set-get подход- управление доступом к полю объекта — семантика присваивания.
Set-get подход разделяет фактическое хранение данных и пользовательское представление о данных, возвращает к вопросу: «Что такое данные? »
Разделение логических и физических данных знакомо по СУБД (view).
С точки зрения процедурного программирования, состояние — это значения переменных, а объектного — несколько иное. К примеру, работаем с декартовыми координатами, а пользователю представляем как полярные.
Идея пользовательского представления данных отражается в виде set-get — подхода, которые подразумевает виртуальные (пользовательские) поля.
Тем самым гарантируется, что при изменении реализации данных, не «посыпятся» программы, которые зависят от этого типа.
Есть поле private, которое недоступно, а есть парочка функций его обслуживающих, где одна записывает, другая возвращает значение
Типы рассматриваются как значения.
//set-get:
class cFraction
{
private int numerator;
private int denominator;
public void add(cFraction a)
{
//…
}
//set-переопределение
//get-вычисляемая функция в точке
// конструктор- эквивалентно write:
cFraction(int x, int y) //set
{
//неявно вызывается системныый конструктор
this. denominator = x;
this. numerator = y;
}
//эквивалентно read:
public int get_denominator()
{
return denominator;
}
public int get_numerator()
{
return denominator;
}
}
Наследование (краткое введение)
Семантика uses в модульном программировании:
Нужно вспомнить понятие модифицированного тела процедуры. После неких синтаксических правок можно считать, что интерфейсные функции определены в том же модуле (в том смысле, что они определены и ими можно пользоваться).
Синтаксические правки заключаются в коллизии имён. Здесь под одним и тем же именем можно было определять разные сущности с одинаковым именем (процедуры, функции, константы, переменные).
Вставал вопрос: как разрешить коллизию?
Сначала родовое имя — имя модуля, а потом точка и название поля.
Наследование реализации как уточнение семантики типа
Наследование синтаксическое — добавление определения новых имён (компонентное программирование основано на нём).
Наследование— иерархия уточнения – разделение сложности при определении типов.
Определение типа — это постепенное уточнение типа (уточнять можно пополнением).
 Понятие наследования – попытка определить понятие подтипа или подкласса, где подкласс — это наследник в смысле ООП.
Понятие наследования – попытка определить понятие подтипа или подкласса, где подкласс — это наследник в смысле ООП.
Наследование имён — пополнение интерфейса. Наследование интерфейса отражает естественный ход программирования как добавление новых имён.
Пополнение и переопределение методов
Отношение пополнения интерфейса
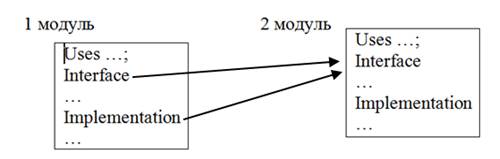
Рис. Наследование определений функций из первого модуля.
Замечание: интерфейс второго модуля более полный.
Наследование интерфейса отражает естественный ход программирования — добавление новых имён.
При этом возможны два случая:
— реализация не меняется (по умолчанию)
— реализация меняется — ссылается на предыдущую
(с точки зрения семантики это означает доопределение (уточнение) значения данного имени). Проще говоря, мы начинаем относиться к функциям как к переменным. Другими словами, тип становится изменяемым атрибутом (одной из характеристик переменной).
Пример: x:=x+1
Существует преобразование, являющееся неявным и естественным – низкая иерархия наследования (т. е. типы могут уточняться (конкретизироваться)). Подобное последовательное переопределение значений имён характерно не только для программирования, но и для любой классификации.
Разного рода иерархии нам нужны для классификации:
Животные