
Классическое определение вероятности
4. Классическое определение вероятности.
Вероятностью события называется отношение числа элементарных исходов, благоприятствующих данному событию, к числу всех равновозможных, образующих полную группу элементарных исходов опыта, в котором может появиться это событие. Вероятность события А обозначим через Р(А), тогда по определению
Р(А) = m/n,
где m — число элементарных исходов, благоприятствующих событию А; n — число всех равновозможных элементарных исходов опыта, в котором может появиться событие А.
Это определение вероятности называется классическим. Оно появилось на начальном этапе развития теории вероятности.
Из определения вероятности события следуют ее простейшие свойства:
1, Вероятность достоверного события равна единице. Действительно, для достоверного события все элементарные исходы являются благоприятствующими этому событию, т. е. m = n. обозначим достоверное событие буквой Е, тогда
Р(Е) = n/n= 1.
2, Вероятность невозможного события равна нулю. В самом деле, для невозможного события нет ни одного элементарного исхода, благоприятствующего этому событию, т. е. m = 0. Обозначим невозможное событие буквой О, тогда Р(О) = 0/n = 0.
3, Вероятность случайного события выражается положительным числом, меньшим единицы. Так для случайного события 0<m<n, то 0 <m/n< 1, 0<P(A) <1.
С л е д с т в и е. вероятность любого события удовлетворяет неравенства 0<=P (A) <= 1.
Классическое определение вероятности предполагает, что число всех элементарных исходов конечно. Но на практике часто встречаются опыты, для которых множество таких исходов бесконечно.
5. Геометрические вероятности и статистическая вероятность.
Понятие геометрической вероятности необходимо, например, при определении вероятности попадания в областьg точки, брошенной в область G, которая содержитg. Когда говорят « в некоторой области брошена точка», имеют в виду, что брошено тело, размерами которого можно пренебречь по сравнению с размерами данных областей (например, поперечным сечением пули по сравнению с площадью мишени, поперечным сечением по сравнению с площадью участка, на котором находятся поражаемые цели).
Общая задача, приведшая к необходимости расширения понятия вероятности, в плоском случае получают следующую формулировку. На плоскости задана квадрируемая область, т. е. область, имеющая площадь. Обозначим эту область буквой G, а ее площадьSG. В области G содержится областьg площадиSg. В области G наудачу бросается точка. Будем считать, что брошенная точка может попасть в некоторую часть областиG с вероятностью, пропорциональной площади этой части и не зависящей от ее формы и расположения. Требуется определить вероятность попадания данной точки в областьg. Пусть А – попадание брошенной точки в область g, тогда геометрическая вероятность этого события определяется формулой P(A) = Sg/SG.
Также существует понятие геометрической вероятности при бросании точки в пространственную областьG, содержащую областьg.
Обозначим меру области g (длину, площадь, объем) через mesg, а меру областиG — через mesG, тогда вероятность попадания в областьg точки, брошенной в областьG, по определению выражается формулой:P(A) = mesg/mesG, где А (рассматриваемое событие) – попадание точки в областьg, которая содержится в областиG. Это определение вероятности называется геометрическим.
Статистическая вероятность – пусть при проведении nиспытаний некоторое событие А появилось mраз. Многочисленные эксперименты такого рода показывают, что при больших nотношение m/n, называемое частью события А, остается примерно постоянным. Статистическое определение вероятности заключается в том, что за вероятность события А принимается постоянная величина, вокруг которой колеблются значения частостей при неограниченном возрастании числа n.
В случае статистического определения вероятность обладает следующими свойствами: 1) вероятность достоверного события равна единице; 2) вероятность невозможного события равна нулю; 3) вероятность суммы двух несовместных событий равна сумме их вероятностей.
6. Теоремы сложения и умножения вероятностей..
Теорема сложения вероятностей несовместных событий. Вероятность появления одного из двух несовместных событий, безразлично какого, равна сумме вероятностей этих событий
Р(А+В) = Р(А) + Р(В).
Следствие 1. Вероятность появления одного из нескольких попарно несовместных событий, безразлично какого, равна сумме вероятностей этих событий
Р(А1 + А2 + … + Аn) = Р(А1) + Р(А2) + … Р(Аn).
Следствие 2. Сумма вероятностей противоположных событий равна 1
Р(А) + Р(А)= 1.
Теорема сложения вероятностей совместных событий. Вероятность появления хотя бы одного из двух совместных событий равна сумме вероятностей этих событий без вероятности их совместного появления
Р(А + В) = Р(А) + Р(В) – Р(АВ).
Теорема может быть обобщена на любое конечное число совместных событий
Р(А1 + А2 + А3 +…+ Аn ) = Р(А1) + Р(А2) + Р(А3) +…+ Р(Аn) – Р(A1A2) — Р(А1А3) — …-P(An-1An) + (А1А2А3) +…+ Р(Аn-2Аn-1Аn) — …+ (-1)n-1Р (А1А2…Аn).
Теорема умножения вероятностей. Вероятность совместного наступления двух событий равна произведению вероятности одного из них на условную вероятность другого, вычисленную в предположении, что первое событие уже наступило
Р(АВ)=Р(А)РА(В).
В частности для независимых событий Р(АВ)=Р(А)Р(В), т. е. вероятность наступления двух независимых событий равна произведению вероятностей этих событий.
Следствие. Вероятность совместного появления нескольких зависимых событий равна произведению вероятности одного из них на условные вероятности всех остальных, вычисленную в предположении, что все предыдущие события уже наступили
Р(А1А2А3…Аn)=P(A1)PA1(A2)PA1*A2(A3)…PA1A2…An-1(An).
В частности, вероятность совместного наступления нескольких событий независимых в совокупности, равна произведению вероятностей этих событий
P(A1A2A3…An)= P(A1)P(A2)…P(An).
48. Основные понятия дисперсионного анализа.
В процессе наблюдения за исследуемым объектом качественные факторы произвольно или заданным образом изменяются. Конкретная реализация фактора называется уровнем фактораили способом обработки. Модель дисперсионного анализа с фиксированными уровнями факторов называется моделью I, модель со случайными факторами – моделью II. Благодаря варьированию фактора можно исследовать его влияние на величину отклика.
В зависимости от количества факторов, определяющих вариацию результативного признака, дисперсионный анализ подразделяется на однофакторный и многофакторный.
Основными схемами организации исходных данных с двумя и более факторами являются:
—перекрёстная классификация, характерная для моделей I, в которых каждый уровень фактора сочетается при планировании эксперимента с каждой градацией другого фактора;
—иерархическая классификация, характерна для модели II, в которой каждому случайному, наудачу выбранному значению одного фактора соответствует свое подмножество значений второго фактора;
**Модель дисперсионного анализа с фиксированными эффектами – устанавливает строго определённые уровни изучаемого фактора.
**Модель со случайными эффектами – уровни значения фактора выбираются исследователями случайно из широкого значения диапазона фактора.
Для дисперсионного анализа однофакторных экспериментов различие этих двух моделей не столь существенно, однако в многофакторном дисперсионном анализе оно может оказаться весьма важным.
При выполнении дисперсионного анализа должны выполняться следующие статистические допущения: независимо от уровня фактора величины отклика имеют нормальный закон распределения и одинаковую дисперсию.
В основе дисперсионного анализа лежит разделение дисперсии на части или компоненты. Вариацию, обусловленную влиянием фактора, положенного в основу группировки, характеризует межгрупповая дисперсия σ2. Она является мерой вариации частных средних по группам χјсред. вокруг общей средней и определяется по формуле:
![]() 2=
2=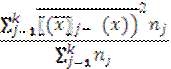 ,
,
где-k. число-групп;
nj-число единиц в j-ой группе;
хj сред.- частная средняя по j-ой группе;
х сред. – общая средняя по совокупности единиц.
Вариацию, обусловленную влиянием прочих факторов, характеризует в каждой группе внутригрупповая дисперсия σ2j.
σ2j = ![]()
Между общей дисперсией σ20, внутригрупповой дисперсией σ2 и межгрупповой дисперсией σ2 сред. существует соотношение: σ20 = ![]() 2 + σ2.
2 + σ2.
Внутригрупповая дисперсия объясняет влияние неучтённых при группировке факторов, а межгрупповая дисперсия объясняет влияние факторов группировки на среднее значение по группе.
7. Условная вероятность.
В ряде случаев приходится рассматривать вероятности событий при дополнительном условии, что произошло некоторое другое событие, имеющее вероятность, отличную от нуля. Такие вероятности называются условными вероятностями.
Вероятность события В при условии, что произошло событие А, называется условной вероятностью события В и обозначается так: Р (В/А), или РА(В).
Например, пусть А – событие, состоящее в извлечении белого шара из урны, содержащей n шаров, в том числе mбелых, n – mчерных; В – событие, состоящее в извлечении белого шара из той же урны после того, как из нее уже извлечен один шар. Очевидно, если первый извлечённый шар был белым, т. е. если произошло событие А, то в урне после первого извлечения останется m – 1 белых иn-mчерных шаров, поэтому вероятность события В будет равнаm-1/n-1. Если же первый извлеченный шар был черным (произошло событие А), то в урне останется mбелых и n-m-1 черных шаров; искомая вероятность окажется равной m/n-1. Следовательно, вероятность события В меняется в зависимости от того, происходит или не происходит событие А, т. е. вероятность события В может принимать два различных значения m-1/n-1, m/n-1.
Таким образом, Р(В/А)=m-1 /n-1, P(B/A)= m/n-1.
В случае классического определения условные вероятности вычисляются аналогично тому, как вычисляются безусловные вероятности. Пусть среди полной группы элементарных исходов А1, А2, …, Аn событию А благоприятствуют m исходов, событию В – kисходов, событию АВ –lисходов (l<=m, l<=k). если событие В произошло, то это означает, что наступило одно из событий Ai, благоприятствующих В, при этомl и только l событийAi, благоприятствующих АВ, поэтому
Р(А/В) = l/k = l/n / k/n = P(AB)/P(B),
P(B/A) = l/m = l/n / m/n = P(AB) / P(A).
Итак, получены следующие формулы:
Р(А/В)=Р(АВ)/Р(В), Р(В/А)= Р(АВ)/Р(А).
При аксиоматическом введении понятия вероятности условные вероятности определяются соответственно формулами:Р(В/А)=Р(АВ)/Р(А), Р(А/В) = Р(АВ)/Р(В).
8. Независимость событий.
Введем понятие независимости одного события от другого. Событие В не зависит от события А, если Р(В/А) = Р(В),
Т. е. вероятность события В не зависит от того, произошло ли событие А.
Из формул Р(АВ)=Р(А)Р(В/А), Р(АВ)= Р(В)Р(А/В) следует, что Р(А)Р(В/А) = Р(В)Р(А/В). Учитывая Р(В/А) = Р(В), получаем Р(А)Р(В) = Р(В)Р(А/В). Отсюда следует, что Р(А/В)=Р(А), так как Р(В) ≠ 0. Это равенство означает, что событие А не зависит от события В.
Таким образом, свойство независимости событий является взаимным.
Если событие А и В независимы, то независимы также события Ā и В, А и ![]() , Ā и
, Ā и ![]() . Докажем независимость событий Ā и В. События А / В и Ā / В противоположны, поэтому Р(А/В) + Р(Ā/В)=1. Поскольку события А и В независимы, т. е. Р(А/В) = Р(А) и Р(В/А) = Р(В), тоР(А) + Р(Ā/В) = 1,
. Докажем независимость событий Ā и В. События А / В и Ā / В противоположны, поэтому Р(А/В) + Р(Ā/В)=1. Поскольку события А и В независимы, т. е. Р(А/В) = Р(А) и Р(В/А) = Р(В), тоР(А) + Р(Ā/В) = 1,
Р(Ā/В) = 1 – Р(А)= Р(Ā), Р(Ā/В) = Р(Ā).
Последнее равенство означает, что Ā не зависит от В. Но в этом случае и В не зависит от Ā, т. е. Ā и ![]() независимы.
независимы.
9. Формулы полной вероятности и Байеса.
Пусть А – произвольное событие, события Н1, Н2, …Нnпопарно – несовместимы и А содержит Н1 + Н2, + …+ Нn. Вероятности событий Нi (I = 1,2,…, n) известны, причем Р(Нi) не равно 0; известны также условные вероятности Р(А/Нi). Требуется найти вероятность события А.
Событие А можно представить в виде суммы попарно-несовместных событий А=Н1А+ Н2А+…+НnA. На основании следствия из аксиомы Р(А1+А2+…+Аn) = P(A1)+P(A2)+…+P(An) имеем
Р(А) = Р(Н1А)+Р(Н2А)+…+Р(НnA).
Применяя теорему умножения вероятностей Р(АВ)=Р(А)Р(В/А), Р(АВ)=Р(В)Р(А/В) находим
Р(Н1А)=Р(Н1)Р(А/Н1),
Р(Н2А) = Р(Н2)Р(А/Н2), …Р(НnА)=Р(Нn)Р(А/Нn).
Подставив эти выражения в предыдущее равенство, получим
Р(А) = Р(Н1)Р(А/Н1)+Р(Н2)Р(А/Н2) +…+Р(Нn)Р(А/Нn) – эта формула называется формулой полной вероятности.
Пусть Н1,Н2,…Нn – попарно-несовместные события, вероятности которых Р(Ні) не равны 0 (і = 1,2,…n), и событие А содержит Н1 + Н2 +…+Нп, для которого известны условные вероятности Р(А/Ні) (і= 1,2,…п). произведем опыт, в результате которого появилось событие А. нужно найти условные вероятности событий Н1,Н2,… НП относительно событий А.
Применяя теорему умножения вероятностей Р(АВ)=Р(А)Р(В/А), Р(АВ)=Р(В)Р(А/В) получаем
Р(АНk) = Р(А)Р(Нk /A) = P(Hk)P(A/Hk),
ОткудаР(Нk/A)= P(Hk)P(A/Hk)/P(A).
Подставим сюда выражение для Р(А) из формулы полной вероятности Р(А)= Р(Н1)Р(А/Н1)+Р(Н2)Р(А/Н2)+…+Р(Нn)Р(А/Нn), получим
P(Hk)/A = P(Hk)P(A/Hk)/суммуP(Hi)P(A/Hi) ,k = (1,2,…n).
Эти формулы называют формулами Байеса.
47. Критерии согласия Пирсона и Колмогорова.
Пусть { x1,x2,….,xn} – выборка из некоторой генеральной совокупности Х, F (x) –предполагаемая функция теоретического распределения. На основании выборки построим интервальный ряд {Δi, ni}, i=1,m, где ni–число элементов выборки, попавших в в интервал Δi = [аі, аі+1). Для каждого интервала Δі вычислим теоретические вероятности Ріпопадания случайной величины Х в интервал Δі:
Pi = P{xϵΔi} = F(ai+ 1) – F(ai).
Число niиnPiназываются эмпирическими и теоретическими частотами. Доказано, что при n →∞ статистика t = ∑(ni – nPi)2/nPi
имеет χ2 – распределение с k = m-r-1 степенями свободы, где m–число интервалов вариационного ряда, r–число параметров теоретического распределения, вычисленных по экспериментальным данным.
Основная гипотеза Н0 состоит в том, что функцией распределения случайной величины Х является выбранная нами теоретическая функция F(x).
Для заданного уровня доверия ϒ по таблицам распределенияχ2к находим критическое значение Χ2к, кр: Р{χ2к<χ2к, кр } = ϒ.
Гипотеза Н0 о согласии экспериментальных данных с распределением F(x) принимается, если t<χ2к, кр.
Заметим, что статистика tимеет распределение χ2 при n→∞, поэтому критерий Пирсона следует применять только при большихn (n> 30).
Критерий Колмогорова заключается в сопоставлении эмпирических Fn(x) и теоретическихF(x) функций распределения. Колмогоров доказал, что какова бы ни была функция распределения F(x) непрерывной случайной величины Х, функция распределения статистики t = √nmax|Fn(x) – F(x)| при n→∞ стремится к функции К(х) = 1 — ∑ (-1)ke-2k2x2.
Задавая доверительную вероятность ϒ, из соотношения К(х) = ϒ можно найти критическое значение хкр.
Гипотеза Н0о согласии экспериментальных данных с функцией распределения F(х)принимается на уровне ϒ, если t<tкр.
В критерии Колмогорова параметры закона распределения F(x) считаются известными заранее, так что заменяя их на выборочные значения, мы всегда привносим некоторую ошибку.
17. Случайные величины и законы их распределения
Опытом называется всякое осуществление определенных условий и действий при
которых наблюдается изучаемое случайное явление. Опыты можно характеризовать
качественно и количественно.
Случайной называется величина, которая в результате опыта может принимать то
или иное значение., причем заранее не известно какое именно. Случайные
величины принято обозначать (X, Y,Z), а соответствующие им значения (x, y,z)
Дискретными называются случайные величины принимающие отдельные
изолированные друг от друга значения, которые можно переоценить.
Непрерывными величины возможные значение которых непрерывно заполняют
некоторый диапазон.
Законом распределения случайной величины называется всякое соотношение
устанавливающее связь между возможными значениями случайных величин и
соответствующими им вероятности.
Ряд и многоугольник распределения.
Простейшей формой закона распределения дискретной величины является ряд
распределения.
|
x |
x1 |
x2 |
x3 |
|
P |
P1 |
P2 |
P3 |
Графической интерпретацией ряда распределения является многоугольник
распределения.
18.Функция распределения случайной величины.
Для непрерывных случайных величин применяют такую форму закона распределения,
как функция распределения.
Функция распределения случайной величины Х, называется функцией аргумента х,
что случайная величина Х принимает любое значение меньшее х (Х<х)
F(х)=Р(Х<х)
F(х) — иногда называют интегральной функцией распределения или интегральным
законом распределения.
Функция распределения обладает следующими свойствами:
1. 0<F(х)<1
2. если х1>х2,то F(х1)>F(х2)
3. 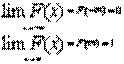
функция может быть изображена в виде графика. Для непрерывной величины это
будет кривая изменяющееся в пределах от 0 до 1, а для дискретной величины —
ступенчатая фигура со скачками.
С помощью функции распределения легко находится вероятность попадания
величины на участок от α до β
Р(α<х<β) рассмотрим 3 события
А — α<Х
В — α<Х<β
С — Х<β
С=А+В
Р(С)=Р(А)+Р(В)
Р(α<х<β)=Р(α)-Р(β)
19. Плотность распределения вероятности непрерывной случайной величины.
Плотность распределения вероятности непрерывной случайной величины Х
называется функция f(х) равная первой производной от функции распределения
F(х)
График плотности распределения называется кривой распределения.
Основные свойства плотности функции распределения:
1. f(х)>0
2. 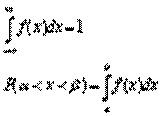
20 Математическое ожидание и дисперсия случайной величины
Математическим ожиданием дискретной случайной величины называется сумма произведений всех ее возможных значений на соответствующие вероятности. Математическое ожидание случайной величины обозначается через М(Х), или ![]() или а. Если дискретная случайная величина принимает конечное число значений х1, х2,…хn соответственно с вероятностями р1, р2,…рn, то по определению М(Х) = х1р1+х2р2+… + хnpn,
или а. Если дискретная случайная величина принимает конечное число значений х1, х2,…хn соответственно с вероятностями р1, р2,…рn, то по определению М(Х) = х1р1+х2р2+… + хnpn, 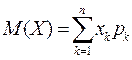
Выясним вероятностный смысл математического ожидания дискретной случайной величины. Пусть в результате n испытаний случайная величина X значение Х1 приняла m1раз, значение х2 – m2 раз, значение хк — mк раз, причем m1 + m2 +… + mk =n. Так как сумма принятых значений равна x1m1 + х2m2 +… + хкmк то среднее арифметическое х всех ее значений определяется формулой
X=х1m1+ х2m2 +… + хкmк /n или x=x1*m1/n+x2*m2/n+….+xkmk/n, x=x1W1+x2W2+….+xkWk, где Wj =mi/n относительная частота значений xi (i = 1, 2, ..,, к). Если n достаточно велико, то относительная частота события приближенно равна его вероятности, т. е. Wk = рк, поэтому получаем приближенную формулу x=x1p1+x2p2+…+xkpk,
Итак, математическое ожидание дискретной случайной величины приближенно равно среднему арифметическому ее возможных значений. Вследствие этого математическое ожидание случайной величины называется ее средним значением.
Замечание.
Математическое ожидание называют также центром распределения. Это название заимствовано из механики и объясняется следующим: если в точках х1,х2,…,хп оси Ох находятся соответственно массы P1Р2,…Рn то координата х центра тяжести системы материальных точек вычисляется по формуле 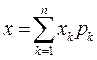 : (
: (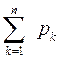 ) . Так как =1, то
) . Так как =1, то 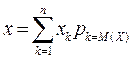
Дисперсией, или рассеянием, случайной величины X называется математическое ожидание квадрата ее отклонения. Дисперсия обозначается через D(X), т. е.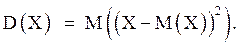 Из определения и свойств математического ожидания следует, что дисперсия любой случайной величины X неотрицательна, т. е.
Из определения и свойств математического ожидания следует, что дисперсия любой случайной величины X неотрицательна, т. е. 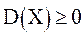 Для вычисления дисперсии применяется формула
Для вычисления дисперсии применяется формула 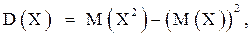
21 Мода и медиана
Мода – величина признака, которая чаще всего встречается в данной совокупности. Применительно к вариационному ряду модой является наиболее часто встречающееся значение ранжированного ряда. Она показывает размер признака, свойственный значительной части совокупности, и определяется по формуле:
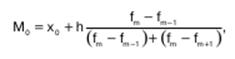
где х 0 нижняя граница интервала;h – величина интервала;f m частота интервала; f m-1 частота предшествующего интервала; f m+1 частота следующего интервала.
Медианой называется вариант, расположенный в центре ранжированного ряда. Медиана делит ряд на две равные части таким образом, что по обе стороны от нее находится одинаковое количество единиц совокупности. При этом у одной половины единиц совокупности значение варьирующего признака меньше медианы, у другой – больше.
Описательный характер медианы проявляется в том, что она характеризует количественную границу значений варьирующего признака, которыми обладает половина единиц совокупности.
При определении медианы в интервальных вариационных рядах сначала определяется интервал, в котором она находится (медианный интервал). Этот интервал характерен тем, что его накопленная сумма частот равна или превышает полусумму всех частот ряда. Расчет медианы интервального вариационного ряда производится по формуле:
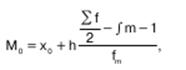
где х 0 нижняя граница интервала;h – величина интервала; f m частота интервала; f – число членов ряда; S m-1 – сумма накопленных членов ряда, предшествующих данному.
22.Моменты случайных величин
Наряду с рассмотренными числовыми характеристиками случайных величин используются и другие, более общие характеристики — начальные и центральные моменты, через которые, в частности, выражаются математическое ожидание и дисперсия.
Начальным моментом k-го порядка, или моментом k-го порядка, случайной величины X называется математическое ожидание k-й степени этой величины, т. е. vk=M(![]() )
)
Если дискретная случайная величина X принимает значения х1,х2,…, хn,… с вероятностями р1,р2,…, рn,… то в соответствии с определением 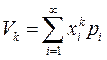 при условии, что этот ряд сходится абсолютно.
при условии, что этот ряд сходится абсолютно.
Центральным моментом k-го порядка случайной величины X называется математическое ожидание k-й степени отклонения этой величины от ее математического ожидания. Обозначив центральный момент k-го порядка через ![]() и положив М(Х)=a, по определению получим
и положив М(Х)=a, по определению получим
![]() Если дискретная случайная величина принимает значение х1,х2,…,хn соответственно с вероятностями р1,р2,…рn…, то
Если дискретная случайная величина принимает значение х1,х2,…,хn соответственно с вероятностями р1,р2,…рn…, то 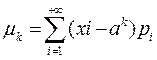 при условии, что ряд сходится абсолютно.
при условии, что ряд сходится абсолютно.
Эксцессом случайной величины Х называется число, определяется формулой ![]() , где
, где ![]() центральный момент четвертого порядка;
центральный момент четвертого порядка;![]() — среднее квадратическое отклонение.
— среднее квадратическое отклонение.
26. Закон Пуассона.
Случайная величина Х распределена по закону Пуассона, если она принимает целые значения k = 0, 1, 2, … с вероятностями ![]() где
где ![]() > 0 – параметр распределения. При этом
> 0 – параметр распределения. При этом 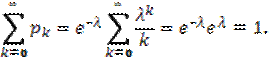
Значения вероятностей ![]() приводятся в таблицах распределения Пуассона.
приводятся в таблицах распределения Пуассона.
Математическое ожидание и дисперсия пуассоновской случайной величины равны параметру распределения: ![]()
Распределение Пуассона используется для приближенных вычислений.
27. Геометрическое и гипергеометрическое распределения.
Дискретная случайная величина Х имеет геометрическое распределение, если она принимает значения k=1, 2, 3, … с вероятностями ![]()
Определение является корректным, т. к. сумма вероятностей 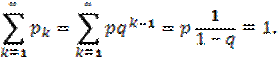
Случайная величина Х, имеющая геометрическое распределение, представляет собой число испытаний Бернулли до первого успеха.
Математическое ожидание и дисперсия Х: ![]()
Дискретная случайная величина Х имеет гипергеометрическое распределение, если она принимает значения m с вероятностями ![]() где m=0,1,…,k; k = min(n, M); M
где m=0,1,…,k; k = min(n, M); M![]() N; n
N; n![]() N.
N.
Вероятность ![]() является вероятностью выбора m объектов обладающих заданным свойством, из множества n объектов, случайно извлечённых (без возврата) из совокупности N объектов, среди кот. Mобъектов обладают заданным свойством.
является вероятностью выбора m объектов обладающих заданным свойством, из множества n объектов, случайно извлечённых (без возврата) из совокупности N объектов, среди кот. Mобъектов обладают заданным свойством.
Математическое ожидание и дисперсия случайной величины, имеющей гипергеометрическое распределение с параметрамиn, M, N: ![]()
![]()
28. Равномерное распределение.
Непрерывная случайная величина Х распределена равномерно на отрезке [a;b], если её плотность вероятности p(x) постоянна на этом отрезке и равна нулю вне его, т. е.
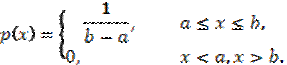
Функция распределения случайной величины, распределённой по равномерному закону, имеет вид 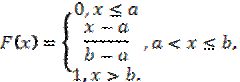
Математическое ожидание и дисперсия равномерной случайной величины: ![]() .
.
31.Функция Лапласа.
Определение. Нормальное распределение с параметрами а = 0, σ = 1 называется нормированным, а его функция распределения
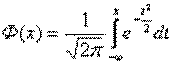 — функцией Лапласа.
— функцией Лапласа.
Замечание. Функцию распределения для произвольных параметров можно выразить через функцию Лапласа, если сделать замену:
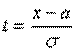 , тогда
, тогда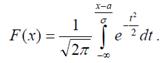
Вероятность попадания нормально распределенной случайной величины на
заданный интервал равна:
![]()
38. Центральная предельная теорема.
Центральная предельная теорема
Пусть ![]() последовательность одинаково распределённых случайных величин с математическими ожиданиями
последовательность одинаково распределённых случайных величин с математическими ожиданиями ![]() и дисперсиями
и дисперсиями ![]() .
.
ТЕОРЕМА. Если случайные величины ![]() независимы и
независимы и ![]() , то при достаточно большом n закон распределения суммы
, то при достаточно большом n закон распределения суммы 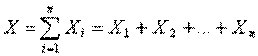 будет сколь угодно близок к нормальному закону распределения
будет сколь угодно близок к нормальному закону распределения ![]() .
.
Так как в условиях теоремы случайные величины независимы, то
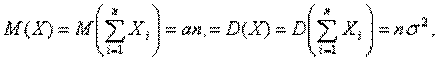
т. е. в условиях теоремы сумма 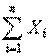 имеет закон распределения близкий к
имеет закон распределения близкий к 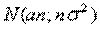 .Так’ как na и
.Так’ как na и ![]() с ростом п, возрастают, то удобнее рассматривать не просто суммы
с ростом п, возрастают, то удобнее рассматривать не просто суммы ![]() , а нормированные суммы
, а нормированные суммы 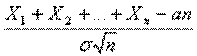 . Такие суммы при
. Такие суммы при ![]() имеют закон распределения
имеют закон распределения ![]() .
.
Если случайная величина может быть представлена в виде суммы большого числа независимых (или слабо зависимых) случайных величин, каждая из которых мала по сравнению с суммой, то эта сумма имеет закон распределения близкий к нормальному.
Вопрос 39. Предмет математической статистики.
Предметомматем. статистики явл. изучение случайных событий и случайных величин по результатам наблюдений. Статистической совокупностьюназывается совокуп. предметов или явлений, объединенных каким-либо общим признаком. Результатом наблюдений над статист. совокуп. явл. статистические данные – сведения о том, какие значения принял в итоге наблюдений интересующий нас признак (случ. величина Х).
Обработка статист. данных методами матем. статистики приводит к установлению определенных закономерностей, присущих массовым явлениям. При этом точность статистис. выводов повышается с ростом числа наблюдений.
Статис. данные, как правило, представляют собой ряд значений {х1, х2,…..,хn}некоторый случайной величины Х. Исследование случайной величины начинается с обработки этого ряда значений. Затем строятся функции, характер. случайную величину. Эти функции назыв. статистиками.
Т. о., статистика – это функция
Т : (х1, х2,…..хn)→ Т (х1, х2,…..хn),
которая набору значений {х1, х2,…..,хn} случайной величины сопоставляет по некоторому правилу действительное число. Статистика явл. функцией от реализаций случайной величины.
В теорет. исследованиях удобно рассматривать статистикуТкак функцию от случайных величин Х1, Х2, ….., Хn, имеющих такое же распределение, как и случайная величина Х:
Т =Т(Х1, Х2,…..Хn).
Т. о., мы рассматриваем случайную величину Х как набор одинаковых случайных величин {Х1, Х2,…..Хn}. В такой трактовке статистика становится случайной величиной и изучение ее распределения приводит к выводам о распределении самой случайной величины Х.
Вопрос 40. Генеральная и выборочная совокупность.
Генеральной совокуп. назыв. совокупность объектов или наблюдений, все элементы которой подлежат изучению при статистич. анализе.
В математ. статист. генер. совокуп. часто понимается как совокуп. всех мыслимых наблюдений, которые могли быть произведены при выполнении некоторых условий. Понятие генер. совокуп. аналогично понятию случайной величины (закону распределения вероятностей), так как обе они полностью определяются заданными условиями.
Генер. совокуп. может быть конечной или бесконечной.
Объемомгенер. совокуп. назыв. число ее объектов (наблюдений).
Выборочной совокупностьюназывается часть объектов генер. совокуп., используемая для исследования.
Сущность выбор. метода в матем. статистике заключ. в том, чтобы по определ. части генеральной совокупности (выборке) судить о ее свойствах в целом.
Выборочный метод явл. единственно возможным в случае бесконечной генеральной совокупности или когда исследование связано с уничтожением (гибелью) наблюдаемых объектов. Для того чтобы по выборке можно было адекватно судить о случайной величине, она должна быть представительной (репрезентативной.)Репрезентативность выборки обеспечивается объемом выборке и случайностью отбора ее элементов, так как все элементы генеральной совокупности должны иметь одинаковую вероятность попадания в выборку.
Имеются 2 способа образования выборки:
1) повторная выборка,когда каждый элемент, случайно отобранный и исследованный, возвращается в общую совокупность и может быть отобран повторно;
2) бесповторная выборка, когда отобранный элемент не возвращается в общую совокупность.
2. Алгебра событий.
Пространством элементарных событий ![]() наз. множество всех элементарных исходов, относящихся к заданному опыту.
наз. множество всех элементарных исходов, относящихся к заданному опыту.
Суммой 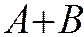 (или объединением
(или объединением 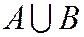 ) 2 событий называется событие, которому благоприятствуют исходы, благоприятствующие событиям
) 2 событий называется событие, которому благоприятствуют исходы, благоприятствующие событиям ![]() или
или ![]() .
.
Произведением 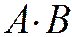 (или пересечением
(или пересечением 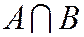 ) 2 событий называется событие, которому благоприятствуют исходы, благоприятствующие одновременно событиям
) 2 событий называется событие, которому благоприятствуют исходы, благоприятствующие одновременно событиям ![]() и
и ![]() .
.
Событие ![]() наз. противоположным событию
наз. противоположным событию ![]() , если событию
, если событию ![]() благоприятствуют все те элементарные исходы, которые не являются благоприятствующими для события
благоприятствуют все те элементарные исходы, которые не являются благоприятствующими для события ![]() .
.
ТЕОРЕМА. Сумма вероятностей противоположных событий = 1.
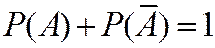
ТЕОРЕМА. Если события ![]() и
и ![]() совместны, вероятность суммы событий = сумме вероятностей этих событий без вероятности их совместного появления.
совместны, вероятность суммы событий = сумме вероятностей этих событий без вероятности их совместного появления.
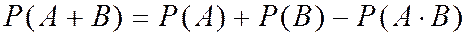
11.Формула Бернулли.
Вероятность того, что в n независимых испытаниях, в каждом из которых вероятность появления события равна р (0 < р < 1), событие наступит ровно r раз (безразлично, в какой последовательности), равна. ![]()
или ![]()
где q=1-p
Вероятность того, что в п испытаниях событие наступит: а) менее k раз; б) более k раз; в) не менее * раз; г) не более k раз, — находят соответственно по формулам:
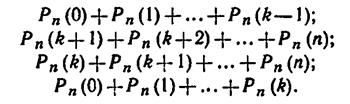
30.Нормальный закон распределения
Непрерывная случайная величина Х имеет нормальный закон распределения (закон Гаусса) с параметрами а и 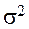 , если ее плотность вероятности имеет вид
, если ее плотность вероятности имеет вид
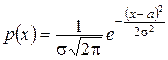 .
.
Кривую нормального закона распределения называют нормальной или гауссовой кривой.
Нормальная кривая симметрична относительно прямой х = а, имеет максимум в точке х = а, равный ![]() , и две точки перегиба
, и две точки перегиба ![]() с ординатой
с ординатой 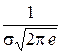 .
.
Для случайной величины, распределенной по нормальному закону, 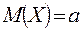 ,
, ![]() .
.
Функция распределения случайной величины Х, распределенной по нормальному закону, выражается через функцию Лапласа Ф(х) по формуле
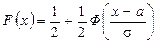 ,
,
где 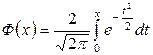 .
.
Вероятность попадания значений нормальной случайной величины Х в интервал ![]() определяется формулой
определяется формулой
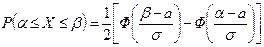 .
.
Вероятность того, что отклонение случайной величины Х, распределенной по нормальному закону, от математического ожидания а не превысит величину ![]() (по абсолютной величине), равна
(по абсолютной величине), равна
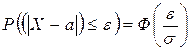 .
.
«Правило трех сигм»: если случайная величина Х имеет нормальный закон распределения с параметрами а и ![]() т. е.
т. е. ![]() , то практически достоверно, что ее значения заключены в интервале
, то практически достоверно, что ее значения заключены в интервале 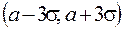
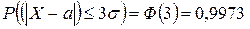 .
.
Асимметрия нормального распределения А = 0; эксцесс нормального распределения Е = 0.
36. Неравенства Маркова и Чебышева
Лемма 1 (неравенство Маркова). Пусть Х — неотрицательная случайная величина, т. е. ![]() . Тогда для любого
. Тогда для любого ![]()
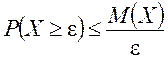 ,
,
где М(Х) — математическое ожидание Х.
Следствие 1. Так как события ![]() и
и ![]() противоположные, то неравенство Маркова можно записать в виде
противоположные, то неравенство Маркова можно записать в виде
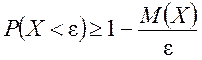 .
.
Лемма 2 (неравенство Чебышева). Для любой случайной величины Х, имеющей конечную дисперсию и любого ![]()
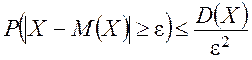 .
.
Следствие 2. Для любой случайной величины Х с конечной дисперсией и любого ![]()
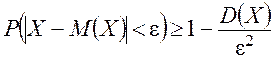 .
.
13.Теорема Пуассона.
Если производится ![]() независимых опытов и вероятность появления события А в
независимых опытов и вероятность появления события А в ![]() -м опыте равна
-м опыте равна ![]() , то при увеличинении
, то при увеличинении ![]() частость
частость ![]() события А сходится по вероятности к среднеарифметическому вероятностей
события А сходится по вероятности к среднеарифметическому вероятностей ![]() :
:
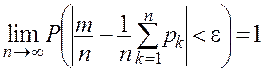 ,
,
где ![]() — сколь угодно малое положительное число. При доказательстве этой теоремы используется неравенство
— сколь угодно малое положительное число. При доказательстве этой теоремы используется неравенство
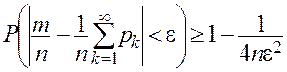 ,
,
имеющее практическое применение.
15. Случайные величины их класификация
Случайная величина – это величина, которая в результате опыта может принять то или иное значение случайным образом с некоторой вероятностью.
Случайные величины могут быть дискретными и непрерывными.
Дискретная случайная величина – это величина, число возможных значений которой конечно или счётно. Например, число попаданий при трех выстрелах(0,1,2,3) или число вызовов, поступивших на телефонную станцию за сутки (0,1,2,3,4,…).
Непрерывная случайная величина – величина, возможные значения которой непрерывно заполняют некоторый промежуток. Например, вес наугад взятого зерна пшеницы или скорость самолета в момент выхода на заданную высоту.
Случайные величины обозначают ![]() , а значения случайных величин
, а значения случайных величин 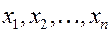 .
.
Закон распределения случайной величины – это всякое соответствие, устанавливающее связь между значениями случайной величины и соответствующими вероятностями.
29.Показательное распределение.
Распределение называется показательным, если плотность вероятности представляется показательной функцией.
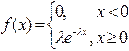
Найдем математическое ожидание случайной величины, распределенной по показательному закону.
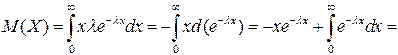
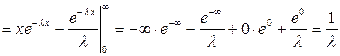
Дисперсию случайной величины найдем аналогично.
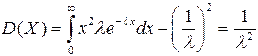
16.Дискретные и Непрерывные величины.
Дискретные случайные величины.
Рассмотрим дискретную случайную величину (ДСВ) ![]() с возможными значениями
с возможными значениями 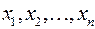 . Каждое значение возможно, но не достоверно. Величина
. Каждое значение возможно, но не достоверно. Величина ![]() может принять каждое значение с некоторой вероятностью.
может принять каждое значение с некоторой вероятностью.
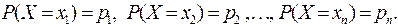
В результате опыта ДСВ ![]() примет одно из этих значений, которые несовместны и образуют полную группу.
примет одно из этих значений, которые несовместны и образуют полную группу. ![]()
Простейшая форма задания значений случайной величины и соответствующих вероятностей – это таблица, которая называется ряд распределения ДСВ ![]() .
.
|
X |
|
|
¼ |
|
|
p |
|
|
¼ |
|
Непрерывные случайные величины.
Вероятность попадания НСВ в точку равна 0.
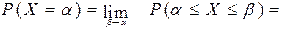
![]()
Вероятности того, что НСВ будет принимать значения на отрезке ![]() и на интервале
и на интервале ![]() , одинаковы.
, одинаковы.
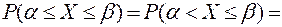
1. случайные события и операции над ними.
Событие наз. случайными, если в результате опыта оно может произойти или не произойти.
Событие наз. достоверным, если оно обязательно появляется в результате данного опыта, и невозможно, если оно не может появиться в этом опыте.
Операции над ними:
Суммой (объединением) событие A и В в некотором опыте наз. событие А+В, состоящее из тех элементарных исходов, которые входят или в событие А, или в событие В или в то и др..
Произведением (пересечением) событий А и В наз. событие А*В, состоящее из элементарных исходов, принадлежащих и в событие А, и событие В, т.е. общих для А и В.
Разность событий А и В наз. событие А-В, состоящее из элементарных исходов, событие А, не принадлежащих событий В.
События А и В считаются равными (А=В), если всякий раз, когда наступает одно из них, наступает другое.
37. Теорема Чебышева и Бернулли.
Теорема Чебышева. Если ![]() последовательность независимых случайных величин с математическими ожиданиями
последовательность независимых случайных величин с математическими ожиданиями 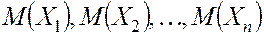 и дисперсиями
и дисперсиями 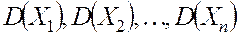 , ограниченными одной и той же постоянной
, ограниченными одной и той же постоянной 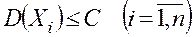 , то какова бы ни была постоянная
, то какова бы ни была постоянная ![]()
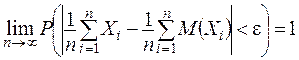 .
.
При доказательстве предельного равенства используется неравенство
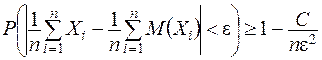 ,
,
которое вытекает из неравенства Чебышева.
Теорема Бернулли. При неограниченном увеличении числа независимых опытов частость появления ![]() некоторого события А сходится по вероятности к его вероятности р = Р(А):
некоторого события А сходится по вероятности к его вероятности р = Р(А): 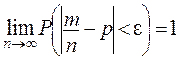 , где
, где ![]() — сколь угодно малое положительное число.
— сколь угодно малое положительное число.
При доказательстве теоремы Бернулли получаем такую оценку 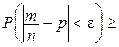
![]() , которая применяется на практике.
, которая применяется на практике.
23.Асимметрия и эксцесс.
Вычисление асимметрии и эксцесса позволяет установить симметричность распределения случайной величины Х относительно M(X)=1 Для этого находят третий центральный момент, характеризующий асимметрию закона распределения случайной величины. Если он равен нулю µ3=0 , то случайная величина x симметрично распределена относительно математического ожидания M(X) Поскольку µ3 имеет размерность случайной величины в кубе, то вводят безразмерную величину — коэффициент асимметрии: 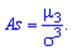
Центральный момент четвертого порядка используется для определения эксцесса, характеризует вершину плотности вероятности F(x) Эксцесс вычисляется по формуле
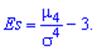
Число 3 вычитается для сравнения отклонения от центрального закона распределения (нормального закона), для которого подтверждается равенство: 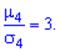
25.Биномиальный закон распределения.
Биномиальное распределение
Пусть имеется n испытаний Бернулли с вероятностью успеха p и вероятностью неуспеха q, p+q=1. Дискретная случайная величина Х – число успехов имеет распределение
Pk = P(Х = K)=Cnk pkqn-k, k=0,1……,n.
Это распределение называется биномиальным с параметрами p и q
Математическое ожидание и дисперсия случайной велчины
MX = np, DX = npq.
26.Функции случайных величин.
Случайной величиной называется функция Х на пространстве событий Ω такая, что для всякого числа х подмножество (Х< х) является событием.
Функцией распределения случайной величины Х называется функция у=F(x), значение которой определяются формулой
F(x)=P(Х< х)
Где P(Х< х) – вероятность событий (Х< х)
Для дискретной случайной величины Х с законом распределения P(Х< хk)=pk, k=1,2,…..,функция распределения имеет вид 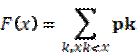
Графиком функции распределения дискретной случайной величины является график кусочно-постоянной функции. Скачки функции F(x) в точке разрыва х=хk равны PK=p(x = Xk).
Функцией распределения непрерывной случайной величины
P(a < X <b) = F (b) – F(a)
Из этого следует что вероятность каждого конкретного значения непрерывной случайной величины равна нулю.
33. многомерные случайные величины.
Многомерной случайной величиной наз. величина, которая при проведении опыта принимает в качестве своего значения не число, а целый набор чисел, заранее не известно каких. Эти наборы, которые случайная величина может принять, образуют множество ее возможных значений. Таким образом, хотя конкретный набор не предугадаешь, он будет из множества возможных наборов (часто это множество хорошо известно).
Понятие многомерной случайной величины аналогично таким понятиям, как система случайных величин или многомерный случайный вектор. Каждое элементарное событие может рассматриваться, как результат сложного испытания, состоящего в измерении всех величин 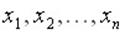 и интерпретироваться, как точка
и интерпретироваться, как точка ![]() – мерного пространства (
– мерного пространства (![]() ) или, как вектор
) или, как вектор 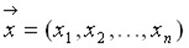 . Каждая из величин
. Каждая из величин 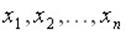 является одномерной случайной величиной и называется составляющей (компонентой). Если говорят, что
является одномерной случайной величиной и называется составляющей (компонентой). Если говорят, что ![]() – случайный вектор (или
– случайный вектор (или ![]() – мерная случайная величина), то величины
– мерная случайная величина), то величины ![]() называют его случайными координатами. Аналогично одномерным случайным величинам различают дискретные многомерные случайные величины (их составляющие дискретны) и непрерывные многомерные случайные величины, которые устроены более сложно (их составляющие непрерывны).
называют его случайными координатами. Аналогично одномерным случайным величинам различают дискретные многомерные случайные величины (их составляющие дискретны) и непрерывные многомерные случайные величины, которые устроены более сложно (их составляющие непрерывны).
14. локальной и интегральной формуле Муавра – Лапласа
Локальная теорема Муавра-Лапласа.
Вычисление вероятности 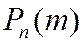 по формуле Бернулли становится затруднительным при больших
по формуле Бернулли становится затруднительным при больших ![]() , поскольку
, поскольку 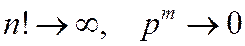 . Поэтому на практике применяют приближенные формулы. Одна из них формула Муавра-Лапласа.
. Поэтому на практике применяют приближенные формулы. Одна из них формула Муавра-Лапласа. 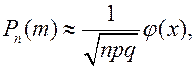
где 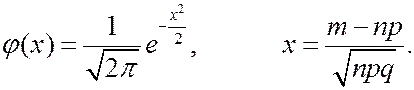
Функция 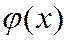 — четная:
— четная: ![]() ; достигает максимума
; достигает максимума 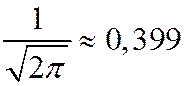 в точке
в точке 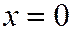 . При этом
. При этом ![]() быстро стремится к нулю с увеличением абсолютной величины
быстро стремится к нулю с увеличением абсолютной величины ![]() :
: 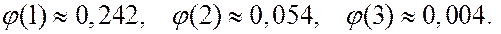
Интегральная формула Муавра-Лапласа.
Если нас интересует вероятность того, что в серии из ![]() испытаний событие
испытаний событие ![]() появится не менее
появится не менее ![]() и не более
и не более ![]() раз, то
раз, то
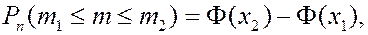
где 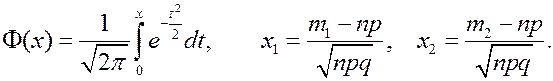
Здесь 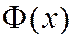 — функция Лапласа. Функция нечетная
— функция Лапласа. Функция нечетная ![]() . При возрастании
. При возрастании ![]() от 0 до
от 0 до ![]() функция
функция ![]() быстро возрастает почти до 0,5.
быстро возрастает почти до 0,5. ![]() ,
, 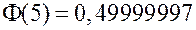 . Можно считать
. Можно считать 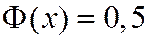 при всех
при всех ![]() .
.
3 Частота и вероятность
Вероятностью события A называют отношение числа благоприятствующих этому событию исходов к общему числу всех единственно возможных и равновозможных исходов испытания.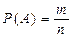
Относительной частотой события называют отношение числа испытаний, в которых событие появилось к общему числу фактически произведенных испытаний.![]()
Вероятность вычисляют до опыта, а относительную частоту — после.
В различных опытах относительная частота изменяется мало (тем меньше, чем больше произвели испытаний) и колеблется возле некоторого постоянного числа — вероятности.
35. Корреляционный момент и коэфф. корреляции.
Корреляционным моментом ![]() случайных величин X и Y называют математическое ожидание произведения их отклонений.
случайных величин X и Y называют математическое ожидание произведения их отклонений.
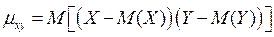
Для дискретных величин
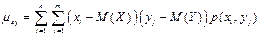
Для непрерывных величин
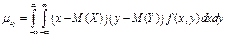
Теорема. Корреляционный момент двух независимых случайных величин равен 0
Коэффициентом корреляции независимых случайных величин X и Y называют отношение корреляционного момента к произведению средних квадратических отклонений этих величин.
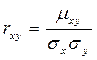
34 Зависимые и независимые случайные величина.
Случайные события называются независимыми, если появление одного из них никак не влияет на вероятность появления других событий.
Для независимых событий справедлива теорема умножения вероятностей: вероятность совместного (одновременного) появления нескольких независимых случайных событий равна произведению их вероятностей:
Р(А1и А2 и А3 … и Аk) = Р(А1) ∙Р(А2) ∙…∙Р(Аk). (7)
Совместное (одновременное) появление событий означает, что происходят события и А1, и А2 ,и А3 … и Аk.
Случайные события А и В называются зависимыми, если появление одного из них, например, А изменяет вероятность появления другого события – В. Поэтому для зависимых событий используются два значения вероятности: безусловная и условная вероятности.
Если А и В зависимые события, то вероятность наступления события В первым (т. е. до события А) называется безусловной вероятностью этого события и обозначается Р(В). Вероятность наступления события В при условии, что событие А уже произошло, называется условной вероятностью события В и обозначается Р(В/А) или РА (В).
Аналогичный смысл имеют безусловная – Р(А) и условная – Р(А/В) вероятности для события А.
Теорема умножения вероятностей для двух зависимых событий: вероятность одновременного наступления двух зависимых событий А и В равна произведению безусловной вероятности первого события на условную вероятность второго:
Р(А и В) = Р(А) ∙Р(В/А) , если первым наступает событие А, или
Р(А и В) = Р(В) ∙Р(А/В), если первым наступает событие В.
12.Найвераятнейшее число успехов в схеме Бернулли.
Число наступлений события Α(успеха) называется наивероятнейшим, если оно имеет наибольшую вероятность по сравнению с вероятностями наступления события Α любое другое количество раз.
ТЕОРЕМА. Наивероятнейшее число наступлений события Αвnиспытаниях схемы Бернулли заключено между числами np– qи np+ p. При этом, если np− q∈Z, то наивероятнейших чисел два: np− qиnp+ p .
Доказательство. Рассмотрим отношение:
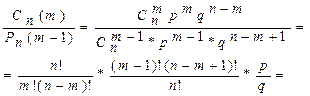
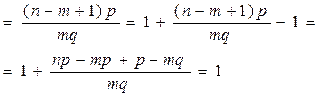
=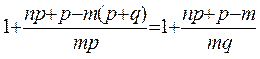
Сравним это отношение с 1, тогда:
1. , при
, при 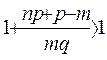 , т. е. np+p>0, т. е. np+ p >m.
, т. е. np+p>0, т. е. np+ p >m.
41. ВАРИАЦИОННЫЙ РЯД И ЕГО ХАРАКТЕРИСТИКИ.
Последовательность вариантов, расположенных в возрастающем порядке, наз. вариационным рядом.
Вариационные ряды бывают дискретными и непрерывными. Дискретным вариационным рядом называется ранжированная последовательность вариантов с соответствующими частотами и (или) частостями.
Вариационные ряды изображают графически с помощью полигона и гистограммы.
Средней арифметическойдискретного ВР называется отношение суммы произведений вариантов на соответствующие частоты к объему совокупности:
Хср=Ʃxini/Ʃni=Ʃxini/n
Модой (Мо’(Х)) ДВР называется вариант, имеющий наибольшую частоту.
Медианой (Ме ‘(Х)) ДВР называется вариант, делящий на две равные части
10. последовательность независимых повторных испытаний.
Пусть А-случайное событие, наблюдаемое в некотором испытании. Отвлекаясь от возможного разнообразия исходов в испытании, будем интересоваться лишь тем, произошло событие A (успех) или не произошло A (неуспех). Пусть P ( A)= p, тогда
P (A) 1 — p = q.
Допустим теперь, что испытание в неизменных условиях повторяется n раз, в силу чего вероятность P ( А)= p остаётся одной и той же в каждом испытании (такие повторные испытания наз. независимыми.)
42., ТОЧЕЧНОЕ и Интервальное ОЦЕНИВАНИЕ ПАРАМЕТРОВ ГЕНЕРАЛЬНОЙ СОВОКУПНОСТИ.
После осуществления выборки возникает задача оценки числовых характеристик генеральной совокупности по элементам выборочной совокупности. Различают точечные и интервальные оценки.
Статистика (функция выборки), используемая в качестве приближенного значения неизвестного параметра генеральной совокупности называется ее точечной оценкой, т. е. точечная оценка это число определяемой по выборке.
Точечные оценки неизвестного параметра Ɵ хороши в качестве первоначальных результатов обработки наблюдений, их недостаток в том, что неизвестно с какой точностью они дают оцениваемый параметр.
Точечная оценка предполагает нахождение единственной числовой величины, которая и принимается за значение параметра
Интервальное оценивание параметров распределения
Оценка неизвестного параметра Ɵ называется интервальной, если она определяется двумя числами – концами интервала.
Интервальной называют оценку, которая определяется двумя числами—концами интервала. Интервальные оценки позволяют установить точность и надежность оценок.
Пусть найденная по данным выборки статистическая характеристика Q* служит оценкой неизвестного параметра Q. Будем считать Q постоянным числом (Q может быть и случайной величиной). Ясно, что Q* тем точнее определяет параметр Q, чем меньше абсолютная величина разности |Q — Q*|. Другими словами, если d>0 и |Q — Q*| <d, то чем меньше d, тем оценка точнее.
Таким образом, положительное число d характеризует точность оценки.
32. Распределение «хи-квардат». Стьюдента и Фишера –Снедекора.
Распределении.
Пусть Х1, Х2, …, Хn — независимые нормально распределенные случайные величины с нулевыми математическими ожиданиями и средними квадратичными отклонениями, = 1. Тогда закон распределения суммы квадратов случайных величин. Χ2=Х21+Х22+…+Х2n наз. законом хи-квадрат с n степенями свободы.
Плотность вероятности такой случайный величины имеет вид.
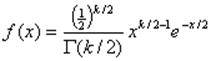
Где Г (n/2)- гамма-функция, для которой выполняется равенство Г(n+2)= n!
Распределение стьюдера
Пусть Х0,Х1, Х2, …, Хn — независимые нормально распределенные случайные величины с нулевыми математическими ожиданиями и средними квадратичными отклонениями, = 1.
Тогда случайная величина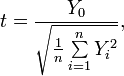 Имеет распределение Стьюдента (t-распределение) с n степенями свободы.
Имеет распределение Стьюдента (t-распределение) с n степенями свободы.
Плотность вероятности случайной величины Т имеет вид f(x)= bn(1+x2/n)- (n+1)/2
Где bn= Г [(n+1)/2]/ Г(n/2)√πn
Распределение Фишера-Снекорда.
Пусть Х1, Х2, …, Хn и Y1,Y2,…, Ym — независимые нормально распределенные случайные величины с нулевыми математическими ожиданиями и средними квадратичными отклонениями, = 1.Тогда случайная величина
Имеет распределение Фишера-Снедекора с n и m степенями свободы.
44. статистические гипотизы.
Пусть Х наблюдаемая дискретная или непрерывная случайная величина.
Статистической гипотезой Н наз. некоторое предположение относительно параметров или вида распределения случайной величины Х, проверяемое по выборочным данным.
Примеры гипотез:
1) генеральная случайная величина Х имеет математическое ожидание M (X)=m0 и дисперсию D(X)=σ 02 ;
2)случайная величина Х, распределённая по показательному закону, имеет параметр λ = 1;
3) случайная величина Х распределена по нормальному закону N (0, 1) ;
4) случайная величина Х распределена по закону Пуассона.
43. Предельная ошибка и необходимость объем выборки.
Предельная ошибка выборки равна t-кратному числу средних ошибок выборки:
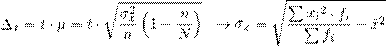
μ – средняя ошибка выборки, рассчитанная с учетом поправки, на которую производится корректировка в случае бесповторного отбора;
t – коэффициент доверия, который находят при заданном уровне вероятности. Так для Р=0,997 по таблице значений интегральной функции Лапласа t=3
![]()
Величина предельной ошибки выборки может быть установлена с определенной вероятностью. Вероятность появления такой ошибки, равной или больше утроенной средней ошибки выборки, крайне мала и равна 0,003 (1–0,997). Такие маловероятные события считаются практически невозможными, а потому вероятность того, что эта разность превысит трехкратную величину средней ошибки, определяет уровень ошибки и составляет не более 0,3%.
В практике организации выборочного наблюдения возникает потребность определения необходимой численности (объема) выборки для обеспечения заданной точности предельной ошибки выборки и ее вероятности. Определение необходимой численности (объема) выборки основывается на формуле предельной ошибки выборки.
Из формулы предельной ошибки выборки среднего значения признака при повторном отборе: ![]()
находим ![]()
При бесповторном случайном отборе необходимая численность выборки вычисляется по формуле:
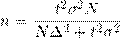
При типической выборке:
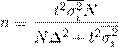
При серийной выборке:
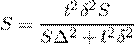
Необходимый объем (численность) выборки при определении доли исчисляется по аналогичным формулам с той разницей, что вместо дисперсии количественного признака, используется дисперсия альтернативного признака. Так, для случайной бесповторной выборки формула необходимой численности выборки будет иметь следующий вид: ![]()
45. Уровень значимости и мощность критерии.
Уровень значимости – это вероятность того, что мы сочли различия существенными, в то время как она на самом деле случайны.
Уровень значимости показывает степень достоверности выявленных различий между выборками, т. е. показывает, насколько мы можем доверять тому, что различия действительно есть.
Уровни значимости:1. 1-й уровень значимости: р ≤ 0,05. Это 5%-ный уровень значимости. До 5% составляет вероятность того, что мы ошибочно сделали вывод о том, что различия достоверны, в то время как они недостоверны на самом деле.
2. 2-й уровень значимости: р ≤ 0,01. Это 1%-ный уровень значимости. Вероятность ошибочного вывода о том, что различия достоверны, составляет не более 1%.
3. 3-й уровень значимости: р ≤ 0,001.
Это 0,1%-ный уровень значимости. Всего 0,1% составляет вероятность того, что мы сделали ошибочный вывод о том, что различия достоверны. Это — самый надёжный вариант вывода о достоверности различий..
Уровень значимости – это вероятность ошибочного отклонения (отвержения) гипотезы, в то время как она на самом деле верна. Речь идёт об отклонении нулевой гипотезы Но.
Мощность критерия – его способность выявлять даже мелкие различия если они есть. Чем мощнее критерий, тем лучше он отвергает нулевую гипотезу.
Здесь появляется понятие: ошибка II рода.
Ошибка II рода – это принятие нулевой гипотезы, хотя она не верна.
Мощность критерий: 1 – β
Чем мощнее критерий, тем он привлекательнее для исследователя. Он лучше отвергает нулевую гипотезу.
46. Проверка статистических гипотез.
Проверка статистических гипотез — один из основных разделов математической статистики, объединяющий методы проверки соответствия статистических данных некоторой статистической гипотезе (гипотезе о вероятностной природе данных). Процедуры проверки статистических гипотез позволяют принимать или отвергать статистические гипотезы, возникающие при обработке или интерпретации результатов наблюдений по многих практически важных разделах науки и производства, связанных со случайным экспериментом.
Теория проверки статистических гипотез позволяет с единой точки зрения трактовать задачи математической статистики, связанные с проверкой гипотез (оценка различия между средними значениями, проверка гипотезы постоянства дисперсии, проверка гипотез независимости, проверка гипотез о распределениях и т. п.). Идеи последовательного статистического анализа, применённые к проверке статистических гипотез, указывают на возможность связать решение о принятии или отклонении гипотезы с результатами последовательно проводимых наблюдений (в этом случае число наблюдений, на основе которых по определённому правилу принимается решение, не фиксируется заранее, а определяется в ходе эксперимента). Основные задачи проверки статистических гипотез могут быть сформулированы в рамках теории статистических решений.
53. Ранговая корреляция
РАНГОВАЯ КОРРЕЛЯЦИЯ— мера зависимости между случайными величинами (наблюдаемыми признаками,переменными), когда эту зависимость невозможно определить количественно с помощью обычного коэффициента корреляции. Процедура установления Р. к. заключается в упорядочении изучаемых объектов в отношении некоторого признака, т. е. им приписываются порядковые номера — ранги (по два номера в соответствии с двумя наблюдаемыми признаками, между которыми исследуется корреляция).. Наиболее распространен коэффициент Р. к. (коэффициент Спирмэна):
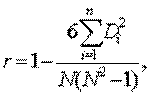
где Di — разница между рангами, присвоенными каждой из переменных i (i = 1, 2, …, n); N — размер выборки. Этот коэффициент принимает значения между +1 и –1, показывая тесноту и направление связи между исследуемыми величинами. Метод Р. к. — один из т. н. непараметрических методов математической статистики.
52. Проверка значимости уравнение и коэффициентов уравнения регрессии.
Для полученного уравнения регрессии определяется ![]() -статистика – характеристика точности уравнения регрессии, представляющая собой отношение той части дисперсии зависимой переменной которая объяснена уравнением регрессии к необъясненной (остаточной) части дисперсии. Уравнение для определения
-статистика – характеристика точности уравнения регрессии, представляющая собой отношение той части дисперсии зависимой переменной которая объяснена уравнением регрессии к необъясненной (остаточной) части дисперсии. Уравнение для определения ![]() -статистики в случае многомерной регрессии имеет вид:
-статистики в случае многомерной регрессии имеет вид:
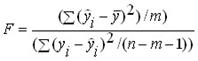
где: 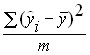 – объясненная дисперсия – часть дисперсии зависимой переменной Y которая объяснена уравнением регрессии;
– объясненная дисперсия – часть дисперсии зависимой переменной Y которая объяснена уравнением регрессии;
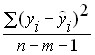 – остаточная дисперсия – часть дисперсии зависимой переменной Y которая не объяснена уравнением регрессии, ее наличие является следствием действия случайной составляющей;
– остаточная дисперсия – часть дисперсии зависимой переменной Y которая не объяснена уравнением регрессии, ее наличие является следствием действия случайной составляющей;
![]() – число точек в выборке;
– число точек в выборке;
![]() – число переменных в уравнении регрессии.
– число переменных в уравнении регрессии.
50. модели и Основные понятия корреляционного и регрессионного анализа
В то же время выделяют корреляционный анализ в узком смысле – когда исследуется сила связи – и регрессионный анализ, в ходе которого оцениваются ее форма и воздействие одних факторов на другие.
Задачи собственно корреляционного анализа сводятся к измерению тесноты связи между варьирующими признаками, определению неизвестных причинных связей и оценке факторов оказывающих наибольшее влияние на результативный признак.
Задачи регрессионного анализа лежат в сфере установления формы зависимости, определения функции регрессии, использования уравнения для оценки неизвестных значении зависимой переменной.
51. линейная корреляционная зависимость и линии регрессии.
Линейная регрессия — используемая в статистике регрессионная модель зависимости одной (объясняемой, зависимой) переменной y от другой или нескольких других переменных (факторов, регрессоров, независимых переменных) x с линейной функцией зависимости.
Модель линейной регрессии является часто используемой и наиболее изученной вэконометрике. А именно изучены свойства оценок параметров, получаемых различными методами при тех или иных предположениях о вероятн-ых характеристиках факторов и случайных ошибок модели. Предельные (асимптотические) свойства оценок нелинейных моделей также выводятся исходя из аппроксимации последних лин-ми моделями. Необходимо отметить, что с эконометрической точки зрения более важное значение имеет линейность по параметрам, чем линейность по факторам модели.
Корреляционная зависимость. Условимся обозначать через Х независимую переменную. а через У—зависимую переменную.
Зависимость величины Y от Х называется функциональной. если каждому значению величины Х соответствует единственное значение величины У.
Если при изменении одной из величин изменяется среднее значение другой, то стохастическая зависимость называется корреляционной.
корреляционная зависимость имеет место, если при изменении х изменяется условное математическое ожидание У.
g(x) =М(У/Х=х) и f(y) = М(Х/У=у) – называются функциями регрессии, а линию на плоскости, соответствующую этому уравнению – линией регрессии соответственно У на Х и Х на У. Эта линия показывает, как в среднем зависит У от Х или Х от У.
49. Однофакторный дисперсионный анализ
Задачей дисперсионного анализа является изучение влияния одного или нескольких факторов на рассматриваемый признак.
Однофакторный дисперсионный анализ используется в тех случаях, когда есть в распоряжении три или более независимые выборки, полученные из одной генеральной совокупности путем изменения какого-либо независимого фактора, для которого по каким-либо причинам нет количественных измерений.
Пусть ![]() – i – элемент (
– i – элемент ( 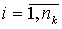 )
) ![]() -выборки (
-выборки ( ![]() ), где m – число выборок, nk – число данных в
), где m – число выборок, nk – число данных в ![]() -выборке. Тогда
-выборке. Тогда ![]() – выборочное среднее
– выборочное среднее ![]() -выборки определяется по формуле
-выборки определяется по формуле
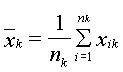 .
.
Общее среднее вычисляется по формуле:
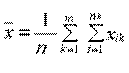 , где
, где 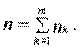
Двухфакторная модель
Одной из используемых моделей данных в дисперсионном анализе является двухфакторная модель. Она состоит в учёте систематических (первый фактор) и случайных (второй фактор) ошибок в определении измеряемых параметров.
Пусть с помощью методов 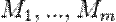 производится измерение нескольких параметров, чьи точные значения —
производится измерение нескольких параметров, чьи точные значения — ![]() . В таком случае, результаты измерений различных величин различными методами можно представить как:
. В таком случае, результаты измерений различных величин различными методами можно представить как:
![]() ,
,
где:
· ![]() — результат измерения
— результат измерения ![]() -го параметра по методу
-го параметра по методу ![]() ;
;
· ![]() — точное значение
— точное значение ![]() -го параметра;
-го параметра;
· ![]() — систематическая ошибка измерения
— систематическая ошибка измерения ![]() -го параметра по методу
-го параметра по методу ![]() ;
;
· ![]() — случайная ошибка измерения
— случайная ошибка измерения ![]() -го параметра по методу
-го параметра по методу ![]() .
.
Тогда дисперсии случайных величин ![]() ,
, ![]() ,
, ![]() ,
, ![]()
выражаются как:
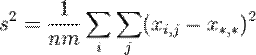
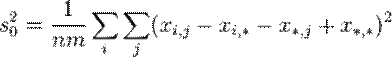
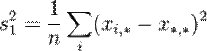
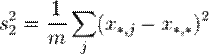
и удовлетворяют тождеству:
![]()


